Understanding different Loss Functions for Neural Networks
Understanding different Loss Functions for Neural Networks

The Loss Function is one of the important components of Neural Networks. Loss is nothing but a prediction error of Neural Net. And the method to calculate the loss is called Loss Function.
In simple words, the Loss is used to calculate the gradients. And gradients are used to update the weights of the Neural Net. This is how a Neural Net is trained.
Keras and Tensorflow have various inbuilt loss functions for different objectives. In this guide, I will be covering the following essential loss functions, which could be used for most of the objectives.
- Mean Squared Error (MSE)
- Binary Crossentropy (BCE)
- Categorical Crossentropy (CC)
- Sparse Categorical Crossentropy (SCC)
Mean Squared Error
MSE loss is used for regression tasks. As the name suggests, this loss is calculated by taking the mean of squared differences between actual(target) and predicted values.
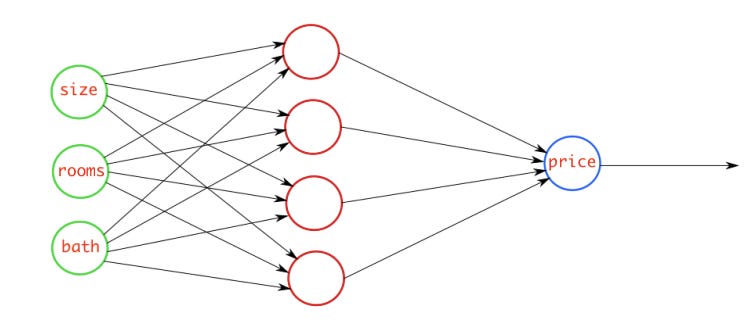
Example
For Example, we have a neural network which takes house data and predicts house price. In this case, you can use the MSE loss. Basically, in the case where the output is a real number, you should use this loss function.
Binary Crossentropy
BCE loss is used for the binary classification tasks. If you are using BCE loss function, you just need one output node to classify the data into two classes. The output value should be passed through a sigmoid activation function and the range of output is (0 – 1).
Example
For example, we have a neural network that takes atmosphere data and predicts whether it will rain or not. If the output is greater than 0.5, the network classifies it as rain and if the output is less than 0.5, the network classifies it as not rain. (it could be opposite depending upon how you train the network). More the probability score value, the more the chance of raining.
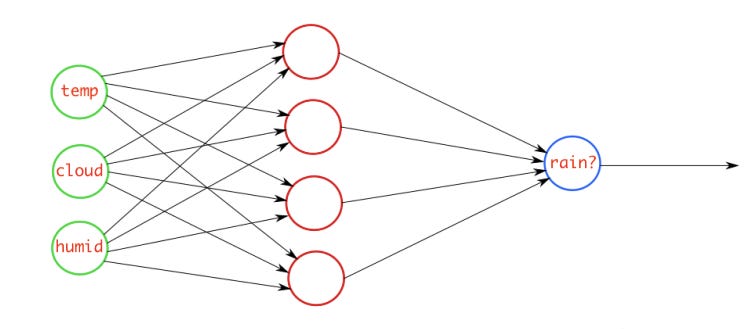
While training the network, the target value fed to the network should be 1 if it is raining otherwise 0.
Note 1
One important thing, if you are using BCE loss function the output of the node should be between (0–1). It means you have to use a sigmoid activation function on your final output. Since sigmoid converts any real value in the range between (0–1).
Note 2
What if you are not using sigmoid activation on the final layer? Then you can pass an argument called from logits as true to the loss function and it will internally apply the sigmoid to the output value.
Categorical Crossentropy
When we have a multi-class classification task, one of the loss function you can go ahead is this one. If you are using CCE loss function, there must be the same number of output nodes as the classes. And the final layer output should be passed through a softmax activation so that each node output a probability value between (0–1).
Example
For example, we have a neural network that takes an image and classifies it into a cat or dog. If the cat node has a high probability score then the image is classified into a cat otherwise dog. Basically, whichever class node has the highest probability score, the image is classified into that class.
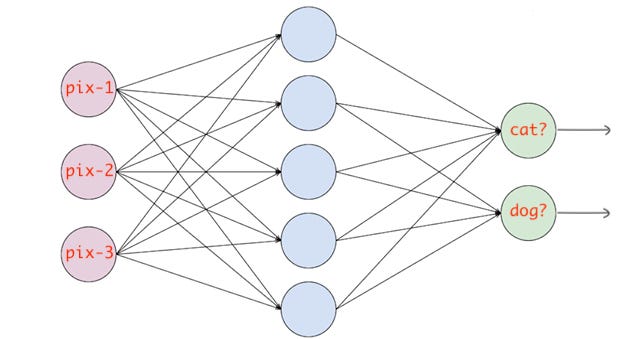
For feeding the target value at the time of training, we have to one-hot encode them. If the image is of cat then the target vector would be (1, 0) and if the image is of dog, the target vector would be (0, 1). Basically, the target vector would be of the same size as the number of classes and the index position corresponding to the actual class would be 1 and all others would be zero.
Note
What if we are not using softmax activation on the final layer? Then you can pass an argument called from logits as true to the loss function and it will internally apply the softmax to the output value. Same as in the above case.
Sparse Categorical Crossentropy
This loss function is almost similar to CCE except for one change.
When we are using SCCE loss function, you do not need to one hot encode the target vector. If the target image is of a cat, you simply pass 0, otherwise 1. Basically, whichever the class is you just pass the index of that class.
These were the most important loss functions. And probably you will be using one of these loss functions when training your neural network



Comments
Post a Comment