What is Gini Impurity?
Gini Impurity
A measurement used to build Decision Trees to determine how the features of a dataset should split nodes to form the tree.
What is Gini Impurity?
Gini Impurity is a measurement used to build Decision Trees to determine how the features of a dataset should split nodes to form the tree. More precisely, the Gini Impurity of a dataset is a number between 0-0.5, which indicates the likelihood of new, random data being misclassified if it were given a random class label according to the class distribution in the dataset.

For example, say you want to build a classifier that determines if someone will default on their credit card. You have some labeled data with features, such as bins for age, income, credit rating, and whether or not each person is a student. To find the best feature for the first split of the tree – the root node – you could calculate how poorly each feature divided the data into the correct class, default ("yes") or didn't default ("no"). This calculation would measure the impurity of the split, and the feature with the lowest impurity would determine the best feature for splitting the current node. This process would continue for each subsequent node using the remaining features.
In the image above,
Mathematical definition
Consider a dataset
The node with uniform class distribution has the highest impurity. The minimum impurity is obtained when all records belong to the same class. Several examples are given in the following table to demonstrate the Gini Impurity computation.
| Count | Probability | Gini Impurity | |||
|---|---|---|---|---|---|
| Node A | 0 | 10 | 0 | 1 | |
| Node B | 3 | 7 | 0.3 | 0.7 | |
| Node C | 5 | 5 | 0.5 | 0.5 |
An attribute with the smallest Gini Impurity is selected for splitting the node.
If a data set
When training a decision tree, the attribute that provides the smallest
In order to obtain information gain for an attribute, the weighted impurities of the branches is subtracted from the original impurity. The best split can also be chosen by maximizing the Gini gain. Gini gain is calculated as follows:
Python Example
Visualizing Gini Impurity range
For a two class problem, Graph of impurity measures as a function of probability of the first class.
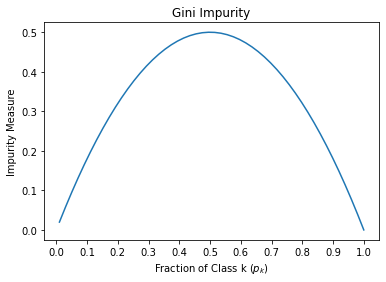
This figure shows that Gini impurity is maximum for the 50-50 sample (
Computation of Gini Impurity for a simple dataset
This data set is used to predict whether a person will default on their credit card. There are two classes ( default = 'yes', no_default = 'no' ):
The figure at the top of this page corresponds to this example


Comments
Post a Comment